 M-STAR (short for Multimodal Self-evolving TrAining for Reasoning) is a project aimed at facilitating multimodal reasoning via self-evolving training.
M-STAR (short for Multimodal Self-evolving TrAining for Reasoning) is a project aimed at facilitating multimodal reasoning via self-evolving training.
In M-STAR, we aim to answer the following questions:
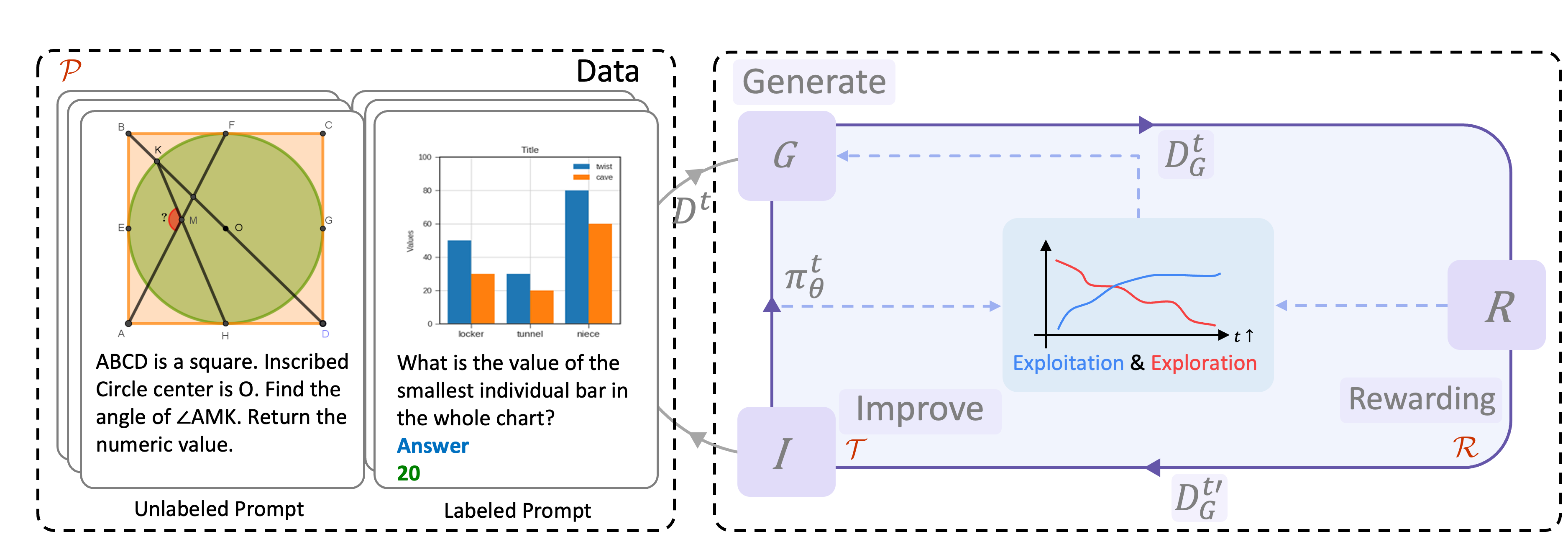
Self-Evolving Training for Multimodal Reasoning can be considered as a loop about: Exploration and Exploitation. This loop operates as a process where the model generates responses (exploration) to various question-image pairs, and learns to maximize the expected reward (exploitation). Through this self-evolution cycle, the model continually refines its performance. This approach enables the model to improve its reasoning abilities without relying on extensive human-annotated data, making it more efficient and scalable for multimodal reasoning.
To comprehensively understand this loop, we delve into the intricacies of self-evolving training for multimodal reasoning, pinpointing three key factors: Training Method, Reward Model, and Prompt Variation. We systematically examine each factor and explore how various configurations affect the training's effectiveness. Our analysis leads to a set of best practices for each factor, aimed at optimizing multimodal reasoning.
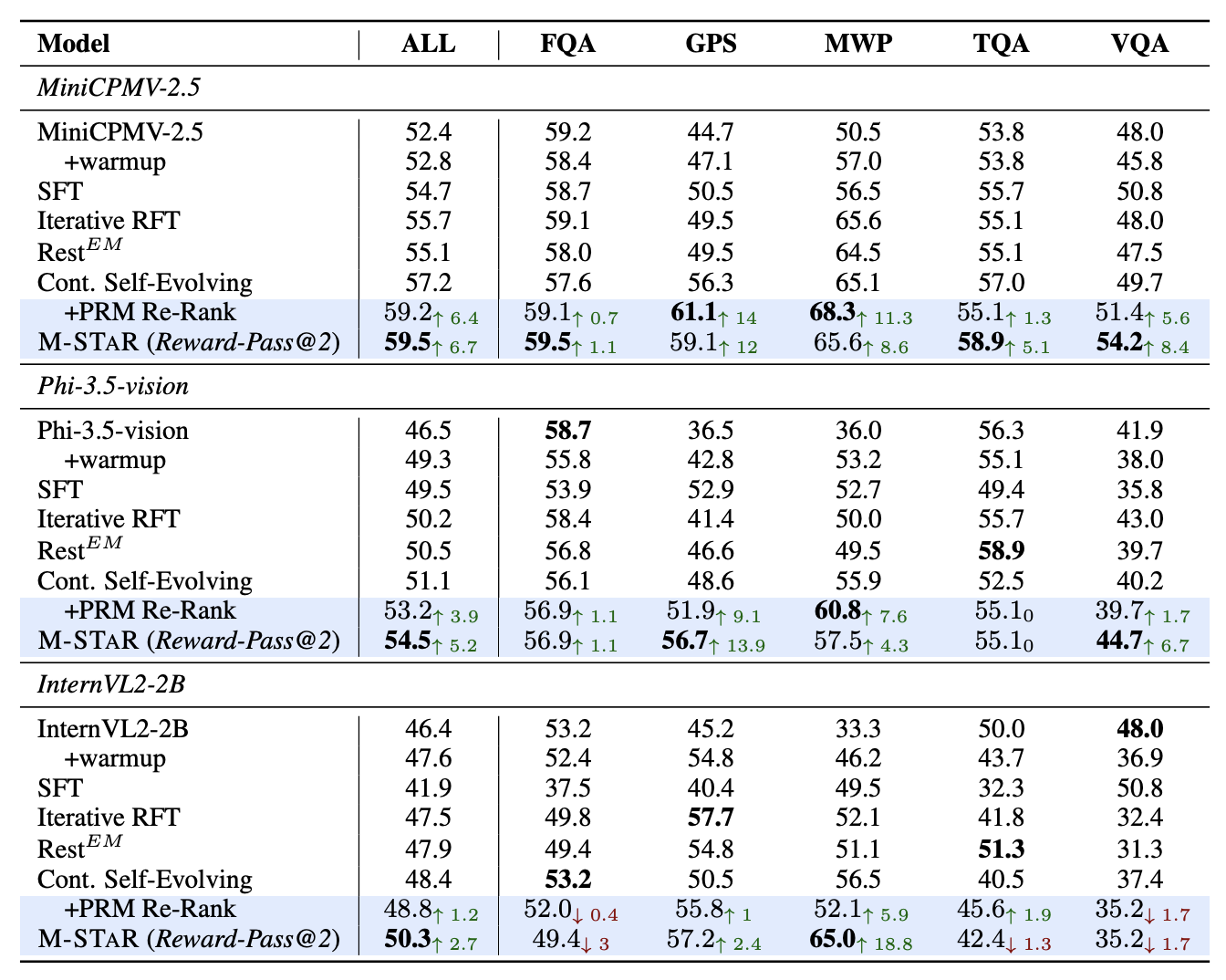
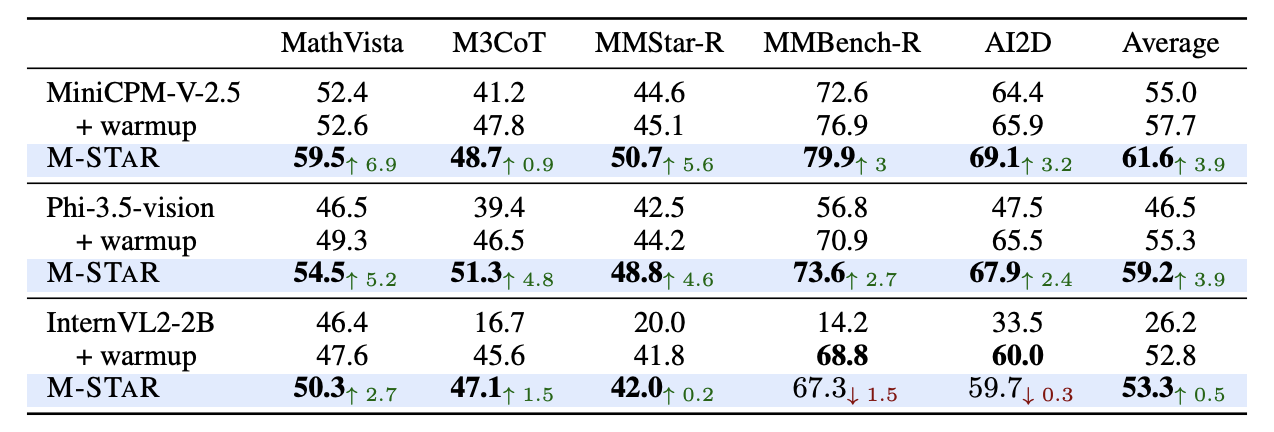
Furthermore, we explore the Self-Evolution Dynamics during training and the impact of automatic balancing mechanisms in boosting performance. After all the investigations, we present a final recipe considering both exploration and exploitation for self-evolving training in multimodal reasoning, encapsulating these design choices into M-STAR framework. M-STAR achieves 59.5% accuracy on MathVista, surpassing the pre-evolved model by 6.9% absolutely without using additional human annotations.

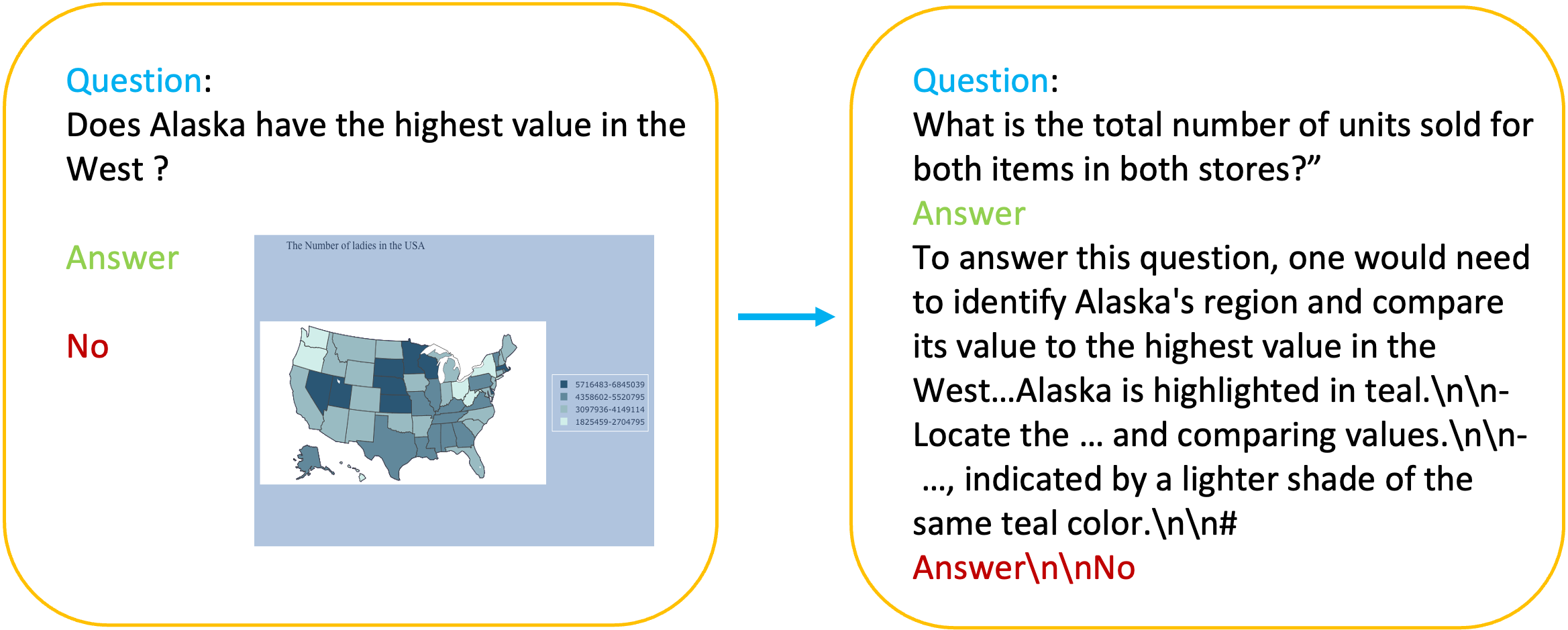
In the realm of multimodal training, Chain-of-Thought (CoT) data is notably scarce, which poses challenges in the development of models capable of generating intermediate reasoning steps. The Warm-Up Phase in our project represents the initial step before self-evolving training, designed to establish a foundational policy model. During this phase, the model is prompted to generate reasoning steps for each input triplet consisting of a question, an image, and an answer. By filtering the responses based on answer accuracy, we conduct warmup training for the policy model, enabling it to begin generating coherent CoT responses. This preparatory phase is crucial in equipping the policy model with the capability to produce intermediate reasoning steps, forming a stepping stone toward more advanced, self-evolving multimodal training.
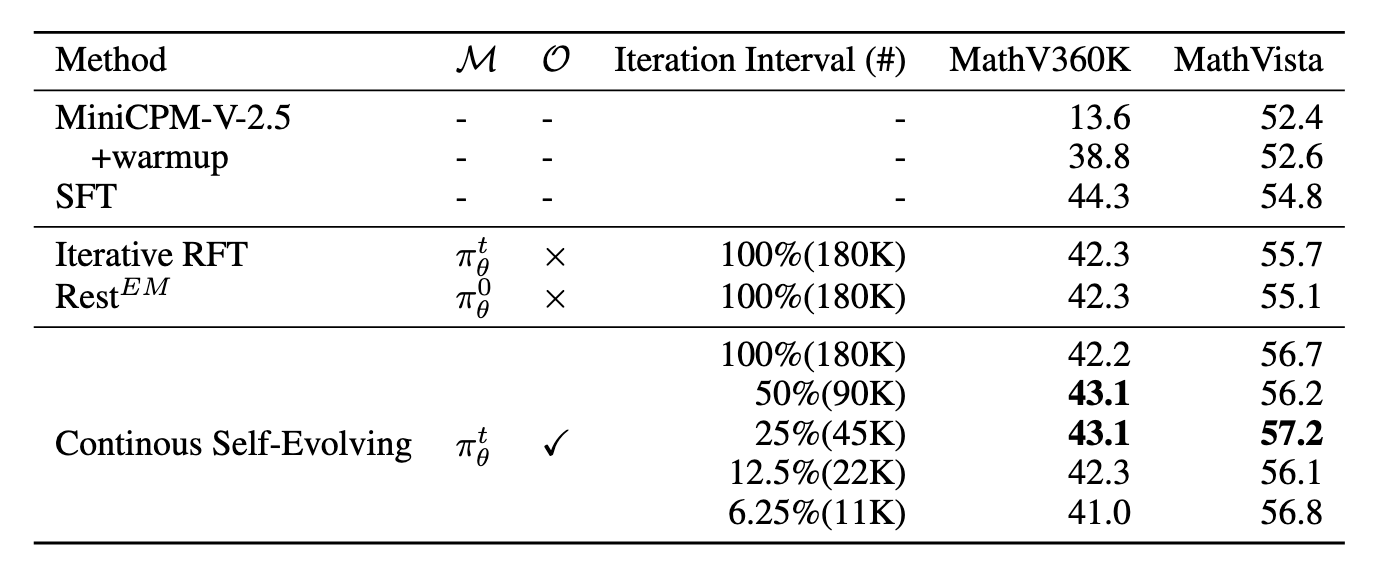
Key findings:

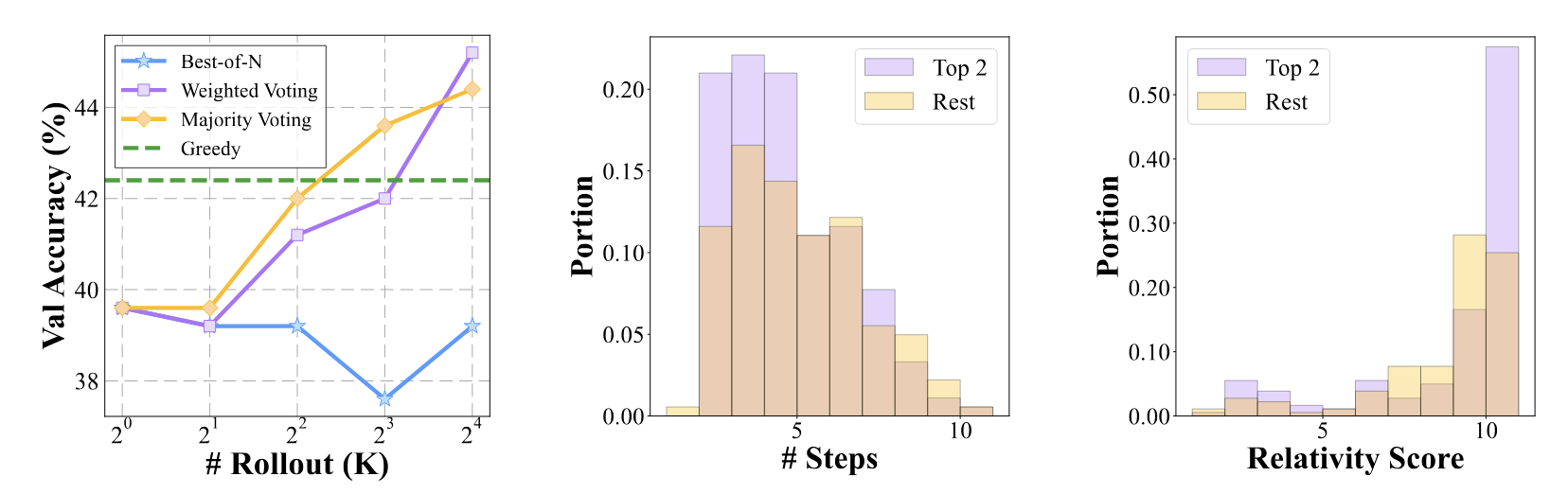
Key findings:
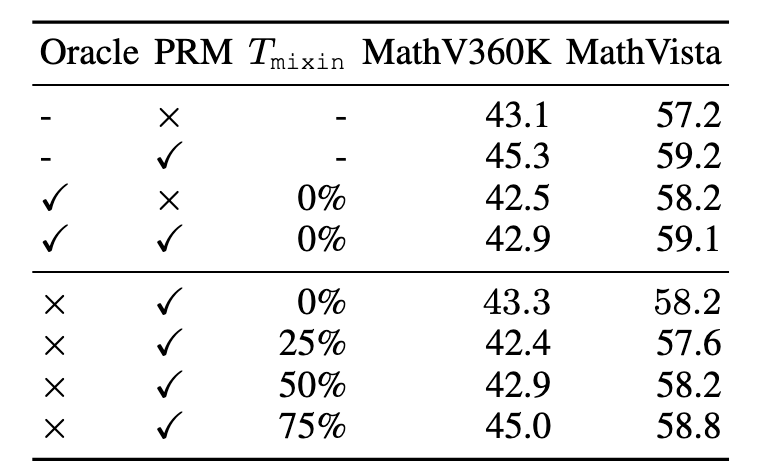
Key findings:
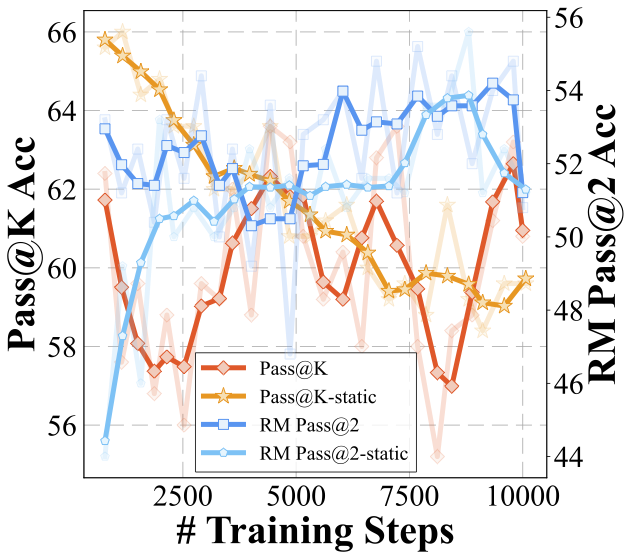
We delve even deeper into the current self-evolution strategy to better understand the bottlenecks. Instead of analyzing from a design space perspective as previously, we now fix the design parameters and focus exclusively on the training dynamics during the model's self-evolution. This shift in focus allows us to examine the process from an orthogonal angle, providing further insights into the underlying mechanisms that drive or impede progress in multimodal reasoning capabilities.
We analyze several key metrics to understand how model changes during the evolution process.
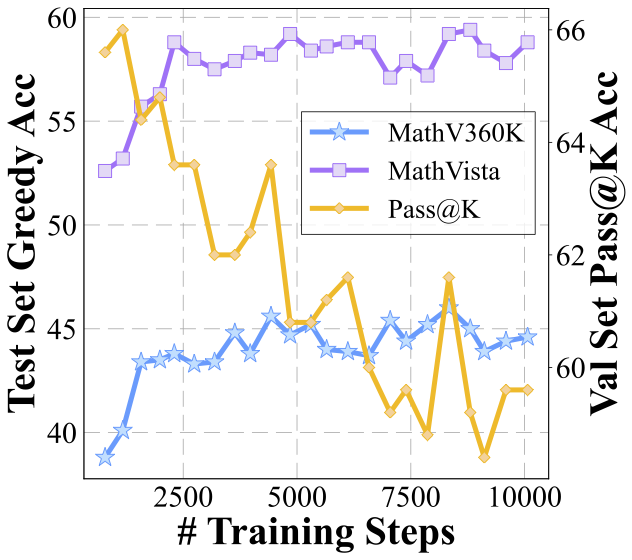
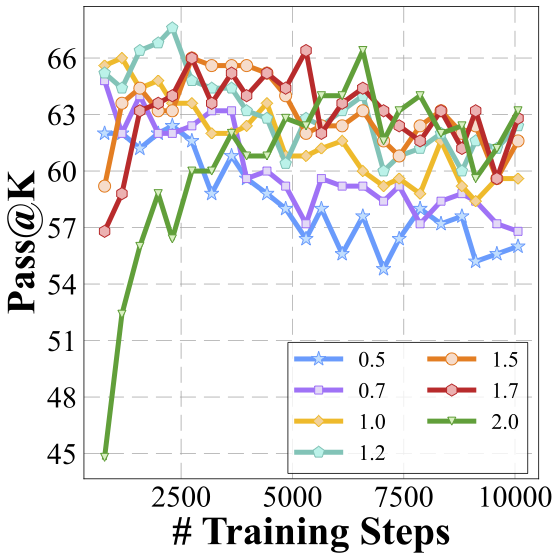
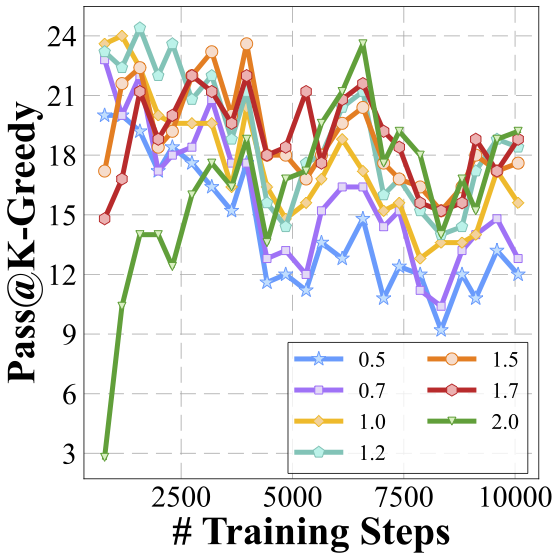
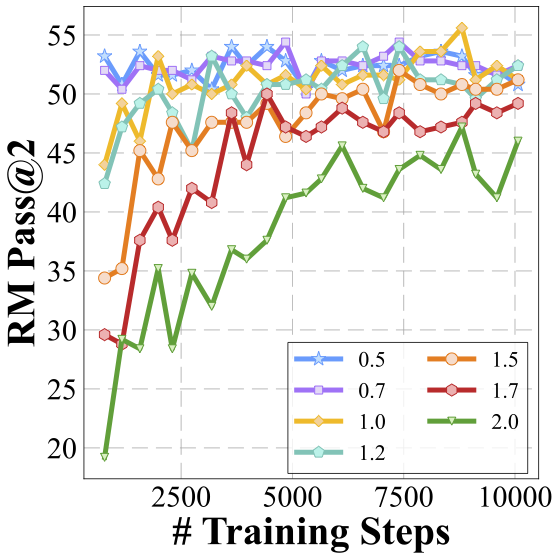
Exploration saturates during the process of self-evolution especially when the temperature is low. How can we enhance exploration to allow the reward model to exploit more effectively?
@misc{liu2024divingselfevolvingtrainingmultimodal,
title={Diving into Self-Evolving Training for Multimodal Reasoning},
author={Wei Liu and Junlong Li and Xiwen Zhang and Fan Zhou and Yu Cheng and Junxian He},
year={2024},
eprint={2412.17451},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.17451},
}